考研真题
1. 中国科学技术大学管理学院《432统计学》[专业硕士]历年考研真题
2. 全国名校应用统计硕士《432统计学》考研真题精选
3. 应用统计硕士《432统计学》名校考研真题(2017年前)
考研指导书
1. 袁卫《统计学》(第5版)配套题库【考研真题精选+课后习题+章节题库】
2. 2026年概率论与数理统计考研题库【考研真题精选+章节题库】

中国科学技术大学管理学院《432统计学》[专业硕士]历年考研真题AI讲解
书籍目录
2012年中国科学技术大学管理学院432统计学[专业硕士]考研真题
2012年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解
2013年中国科学技术大学管理学院432统计学[专业硕士]考研真题
2013年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解
2014年中国科学技术大学管理学院432统计学[专业硕士]考研真题
2014年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解
2015年中国科学技术大学管理学院432统计学[专业硕士]考研真题
2015年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解
2016年中国科学技术大学管理学院432统计学[专业硕士]考研真题
2016年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解

部分内容
2012年中国科学技术大学管理学院432统计学[专业硕士]考研真题




2012年中国科学技术大学管理学院432统计学[专业硕士]考研真题及详解
一、单项选择题(本题包括1~10题,每小题3分,共30分)
1假设一个袋子中有黑色、白色和红色三种颜色的球,它们的比例为3:4:3,现每次有放回地从袋子随机摸出一个球,记下被摸出球的颜色,如此反复,则白球比黑球先被摸出的概率为( )。
A.3/7
B.4/7
C.4/10
D.3/10
【答案】B
【解析】与每次取到的球是红色无关,所以此问题等价于袋中有黑色球:白色球=3:4,求第一次摸球摸到白色球的概率。
2设A,B表示两个随机事件,若P(AB)=0,则事件A,B( )。
A.互斥
B.不同时发生
C.相互独立
D.以上都不对
【答案】D
【解析】举例说明:取X=[-1,1],A=“x∈[-1,0]”,B=“x∈[0,1]”,则
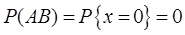
ABC三项均不正确。
3投掷一枚硬币n次,若记其中正面和反面出现的次数分别为x和y,则x和y的相关系数为(
)。
A.0
B.0.5
C.-1
D.1
【答案】C
【解析】相关系数又称线性相关系数。它是衡量变量之间线性相关程度的指标。样本相关系数用r表示,总体相关系数用ρ表示,相关系数的取值范围为[-1,1]。|r|值越大,误差越小,变量之间的线性相关程度越高;|r|值越接近0,误差越大,变量之间的线性相关程度越低。相关系数的公式为:
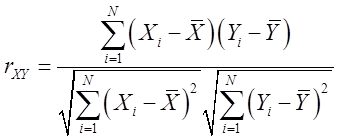
x与y的关系是:x+y=n,y=n-x。x与y的关系是线性相关关系。x的系数-1即为x与y的相关系数。
4假设X1,…,Xn为从正态总体_N(μ,σ2)中抽取的简单随机样本,其中μ,σ2均未知,记样本均值和样本方差分别为 和S2,则
和S2,则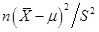 的分布为( )。
的分布为( )。
A.自由度是n-1的f分布
B.自由度是n的t分布
C.自由度是1,n的F分布
D.自由度是1,n-1的F分布
【答案】D
【解析】令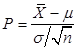 ,
,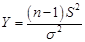 ,则
,则
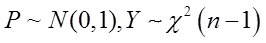
且P,Y独立,则
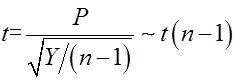
即服从自由度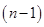 的
的 分布。
分布。
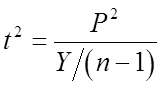
其中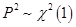 ,得到
,得到
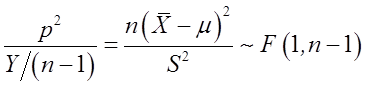
即服从自由度为1,n-1的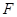 分布。
分布。
5假设X1,…,Xn为从正态总体N(μ,1)中抽取的简单随机样本,其中μ未知,如果要求μ的95%置信区间的长度不超过0.6,则样本量n至少需要等于( )。
A.42
B.43
C.44
D.45
【答案】B
【解析】因为总体方差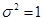 已知,故采用
已知,故采用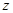 统计量。要求
统计量。要求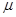 的95%置信区间的长度不超过0.6,即
的95%置信区间的长度不超过0.6,即
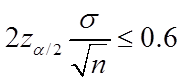
解得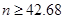 ,所以样本量n至少需要等于43。
,所以样本量n至少需要等于43。
6若一个参数的估计量值为2.4,该估计量的标准差值为0.2,则该参数的一个约95%置信区间为( )。
A.[2.008,2.792]
B.[2.0,2.8]
C.[2.2,2.6]
D.[2.071,2.729]
【答案】B
【解析】根据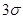 原则,约有68%的数据落在
原则,约有68%的数据落在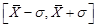 之内;约有95%的数据落在
之内;约有95%的数据落在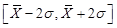 之内;约有99%的数据落在
之内;约有99%的数据落在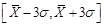 之内。所以该参数的一个约95%置信区间为:
之内。所以该参数的一个约95%置信区间为:
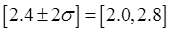
7某保险公司多年的统计资料表明,在家庭财产保险中被盗索赔占20%,以X表示随机抽查100个家庭财产保险中因被盗向保险公司索赔的户数,则可以以95%的把握得出其中至少有( )户会因被盗而向银行索赔。
A.13
B.12
C.15
D.14
【答案】A
【解析】样本容量n=100可视为大样本,当总体方差未知时,可采用样本方差代替总体方差,样本方差为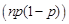 ,选用
,选用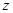 统计量。则π(因被盗而向银行索赔的住户数)的95%置信区间为
统计量。则π(因被盗而向银行索赔的住户数)的95%置信区间为
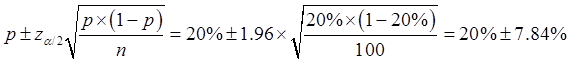
得置信下限为12.16%,
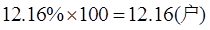
即至少有13户会因被盗而向银行索赔。
8若X1,…,Xn为从总体x中抽取的简单随机样本,则经验分布函数
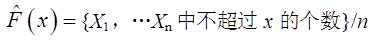
为总体分布F(x)的一个估计。则对固定的x,估计量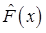 的方差为( )。
的方差为( )。
A.nF(x)(1-F(x))
B.F(x)(1-F(x))/n
C.F2(x)
D.(1-F(x))2
【答案】B
【解析】
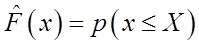
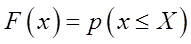
估计量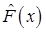 的方差为
的方差为
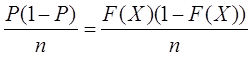
9设X为连续型随机变量,g为一连续函数,则g(X)也为连续型随机变量。该说法(
)。
A.正确
B.错误
【答案】B
【解析】定理:设随机变量 具有概率密度
具有概率密度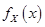 ,
, ,又设函数
,又设函数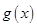 处处可导且恒有
处处可导且恒有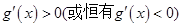 ,则
,则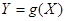 是连续型随机变量。
是连续型随机变量。
由于函数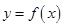 在点
在点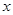 处可导,则函数在该点必连续,但是一个函数在某点连续却不一定在该点处可导。由此可知连续性随机变量
处可导,则函数在该点必连续,但是一个函数在某点连续却不一定在该点处可导。由此可知连续性随机变量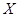 的函数
的函数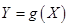 不一定是连续型的随机变量。
不一定是连续型的随机变量。
10设X,Y和Z都是均值为0,方差为1的随机变量,若X和Y的相关系数为0,Y和Z的相关系数为1,则X和Z的相关系数为( )。
A.0
B.1
C.0.5
D.无法得到
【答案】A
【解析】X和Y的相关系数为0,
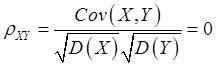
得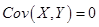 ,Y和Z的相关系数为1,则存在常数
,Y和Z的相关系数为1,则存在常数 ,
,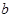 ,使得
,使得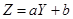 ,得
,得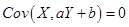 。
。
二、简答题(每题8分,共40分)
1试写出概率的公理化定义。
答:设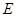 是随机实验,
是随机实验,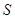 是它的样本空间。对于
是它的样本空间。对于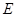 的每一事件
的每一事件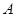 赋予一个实数,记为
赋予一个实数,记为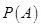 ,称为事件
,称为事件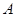 的概率,如果集合函数
的概率,如果集合函数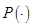 满足下列条件:
满足下列条件:
①非负性:对于每一个事件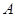 ,有
,有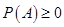 ;
;
②规范性:对于必然事件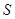 ,有
,有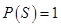 ;
;
③可列可加性:设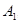 ,
,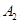 ,
,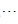 是两两互不相容的事件,即对于
是两两互不相容的事件,即对于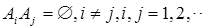 ,有
,有
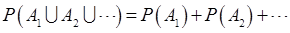
2试解释随机变量的联合分布和边际分布之间的关系。
答:①联合分布可以惟一地确定边际分布;
②边际分布不能惟一确定联合分布;
联合分布:
设(X,Y)是二维随机变量,对于任意实数x,y,二元函数:
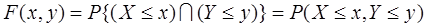
称为二维随机变量(X,Y)的分布函数,或称为随机变量X和Y的联合分布函数。
边际分布:
如果在二维随机变量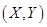 的联合分布函数F(x,y)中令
的联合分布函数F(x,y)中令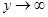 ,由于
,由于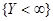 为必然事件,故可得
为必然事件,故可得
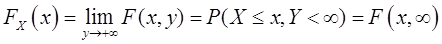
此分布函数称为X的边际分布,记为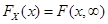 。
。
类似地,在F(x,y)中令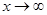 ,可得Y的边际分布为
,可得Y的边际分布为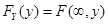 。
。
3“正态随机变量的线性组合仍服从正态分布”这种说法是否正确?为什么?
答:“正态随机变量的线性组合仍服从正态分布”这种说法不正确。
利用连续型随机变量的卷积公式可以得到:有限个相互独立的正态随机变量的线性组合仍然服从正态分布,只有独立的正态随机变量才服从正态分布。若随机变量不相互独立,其线性组合不一定服从正态分布。
即,若
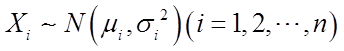
且它们相互独立,则对任意不全为零的常数a1,a2,L,an,有
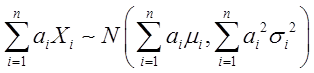
4试指出置信区间和假设检验之间的等价性.
答:置信区间是指由样本统计量和显著性水平所构造的总体参数的估计区间。在统计学中,一个概率样本的置信区间是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一定概率”。这个概率被称为置信水平。
假设检验是数理统计学中根据一定假设条件由样本推断总体的一种方法。具体作法是:根据问题的需要对所研究的总体作某种假设,记作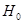 ;选取合适的统计量,这个统计量的选取要使得在假设
;选取合适的统计量,这个统计量的选取要使得在假设 成立时,其分布为已知;由实际样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设
成立时,其分布为已知;由实际样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设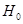 的判断。
的判断。
对同一问题的参数判断检验时,二者使用同一样本、同一统计量、同一分布,因而两者可以相互转换。区间估计问题可以转换成假设检验问题,假设检验问题也可以转换成区间估计问题。区间估计中的置信区间是假设检验中的接受域,置信区间以外的区域就是假设检验中的拒绝域。
5试比较矩估计方法和极大似然估计方法的特点.
答:①矩估计方法:
用样本矩来估计总体矩,用样本矩的连续函数来估计总体矩的连续函数,具体做法:
令
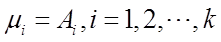
这是一个包含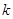 个未知参数
个未知参数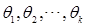 的方程组,解其中的
的方程组,解其中的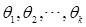 。用方程组的解
。用方程组的解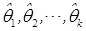 分别作为
分别作为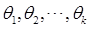 的估计量,这个估计量称为矩估计量,估计量的观察值称为矩估计值。
的估计量,这个估计量称为矩估计量,估计量的观察值称为矩估计值。
②极大似然估计法:
若总体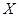 的密度函数为
的密度函数为
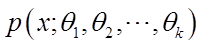
其中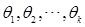 是未知参数,
是未知参数,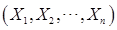 是来自总体
是来自总体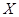 的样本,称
的样本,称
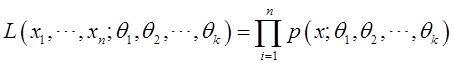
为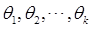 的似然函数,若有
的似然函数,若有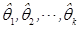 使得
使得
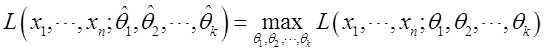
成立,则称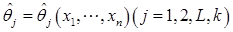 为
为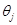 的极大似然估计量,估计量的观察值称为极大似然估计值。
的极大似然估计量,估计量的观察值称为极大似然估计值。
两种方法的比较如下:
(1)矩法估计量与极大似然估计量不一定相同;
(2)用矩法估计参数比较简单,但有信息量损失;
(3)极大似然估计法精度较高,但运算较复杂;
(4)不是所有极大似然估计法都需要建立似然方程。
三、计算分析题(共80分)
1某地方银行对其信用卡制度进行审核并考虑收回部分信用卡。过去,大约有5%的信用卡持有者不履行债务并造成银行无法收回的坏账。因此,管理层认为某特定的信用卡持有者不履行债务的先验概率为0.05。该银行进一步发现,最终履行债务的信用卡持有者有0.20的概率会拖欠一个或几个月后支付。当然,对不履行债务的信用卡持有者,拖欠一个或几个月支付的概率为1。则
(1)(8分)如果某个信用卡持有者已经拖欠了一个月的支付,计算他将不履行债务的概率。
(2)(7分)如果某个信用卡持有者不履行债务的概率超过了0.20,银行就会收回他的信用卡。如果某信用卡持有者已经拖欠了一个月的支付,则银行是否会收回他的信用卡?为什么?
解:(1)记事件A=“信用卡持有者履行债务”,
事件B=“信用卡持有者履行债务中拖欠一个或几个月后支付”,则
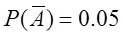
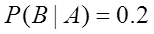
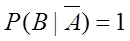
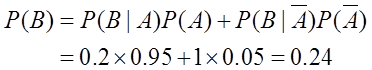
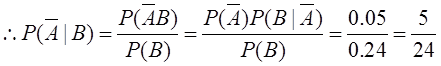
即某个信用卡持有者已经拖欠了一个月的支付,他将不履行债务的概率为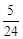 。
。
(2)由上题计算可得,如果信用卡持有者拖欠了一个月的支付,他不履行债务的概率为0.208,超过了0.20(0.208>0.2),此时,银行应该收回他的信用卡。
2假设从X和Y,各有分布

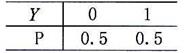
且X和Y不相关,试
(1)(7分)求X和Y的联合分布。
(2)(8分)求Var[X|Y=0]和E[X|Y=0]。
解:(1)由于X与Y不相关,其相关系数为0。则
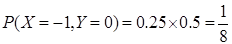
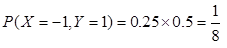
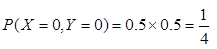
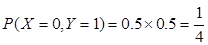
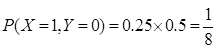
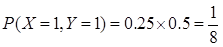
X和Y的联合分布为:
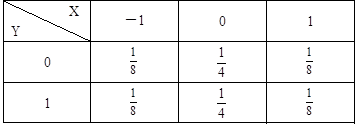
(2)由条件概率公式知
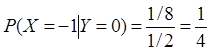
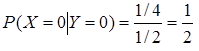
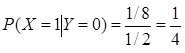
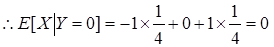
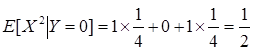
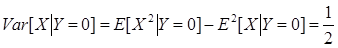
3Street Insider.com报道了2002年一些著名公司的每股收益的数据。在2002年之前,财务分析家就预测了这些公司2002年的每股收益,利用下面数据评论实际的和预测的每股收益的差异。
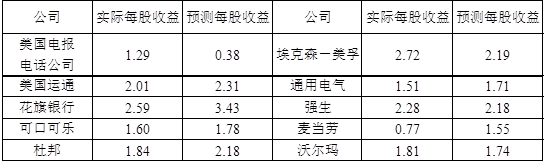
试求:
(1)(7分)在显著性水平0.05下,检验实际的和预测的每股平均收益之间是否存在差异,你的结论是什么?
(2)(4分)两均值之差的点估计是多少?分析家是低估了还是高估了每股的收益?
(3)(4分)给出两均值之差的95%置信区间,并据此对(1)的检验问题作出结论并解释。
解:(1)用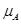 表示实际每股的平均收益,
表示实际每股的平均收益,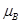 表示预测每股的平均收益。
表示预测每股的平均收益。
提出假设: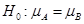 ;
;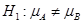
由于总体方差未知且不知道它们是否相同,n=10为小样本数据,所以应该采用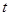 检验统计量:
检验统计量:
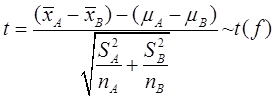
其中,自由度f的计算公式为:
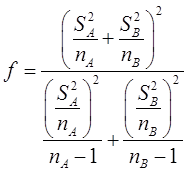
代入数据计算得到: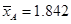 ,
,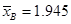 ,
,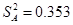 ,
,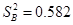 ,
,
t=-0.337,∣t∣<t0.025(17)=2.11
故不能拒绝原假设,认为实际的和预测的每股平均收益之间不存在差异。
(2)由(1)可知两均值之差的点估计为:
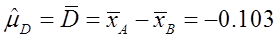
即分析家高估了每股的收益。
(3)由(1)可知,两均值之差的95%置信区间为:
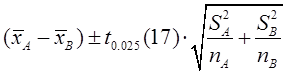
代入数据计算得到两均值之差的95%置信区间为:(-0.748,0.542)。
可知两均值之差的95%置信区间包含了零值,即验证了(1)中认为实际的和预测的每股平均收益之间不存在差异的结论。
4美国睡眠基金会用一个抽样调查来研究每晚睡眠时间是否与年龄有关(Newsweek,2004.1.19)。下面是一个49岁及以下的样本和一个50岁及以上的样本提供的周日夜晚的睡眠时间数据。
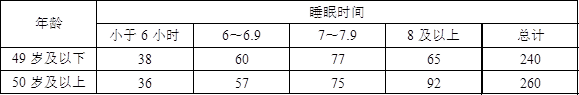
试
(1)(10分)使用独立性检验以确定周日夜晚的睡眠时间年龄是否有关,并给出原假设。在显著性水平为0.05下,能得到什么结论?
(2)(5分)根据(1)的结论分析周日夜晚睡眠时间小于6小时、6~6.9小时、7~7.9小时和8小时及以上的人们的比例的差异,能得到什么结论?给出一个可能的合理解释。
解:(1)列联表独立性卡方检验的基本原理:
令样本量为n,列联表中行、列变量的水平个数分别为r和s,每个单元格中的观测频数为Oij,期望频数为Eij。设列联表中各行的合计值分别为 ,各列的合计值分别为
,各列的合计值分别为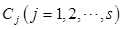 。在原假设成立的条件下,即列联表中行、列变量相互独立时,有:
。在原假设成立的条件下,即列联表中行、列变量相互独立时,有:
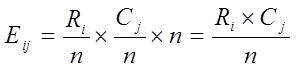
且观测频数Oij与期望频数Eij应相差不大。构造检验统计量:
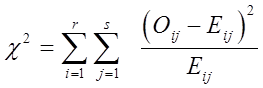
该统计量服从自由度为(r﹣1)(s﹣1)的卡方分布。当该统计量的值很大时,就有理由拒绝原假设,认为这两个变量不相互独立。
对于本例,提出原假设和备择假设:
H0:周日夜晚的睡眠时间与年龄无关(行、列变量相互独立)v.s.H1:周日夜晚的睡眠时间与年龄有关
根据观测频数的列联表,算得期望频数列联表如下:
期望频数列联表
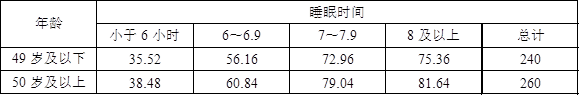
计算得到检验统计量χ2=4.007<χ20.05(3)=7.815,故在0.05的显著性水平下不能拒绝原假设,认为睡眠时间与年龄无关。
(2)由(1)可知,周日夜晚睡眠时间小于6小时、6~6.9小时、7~7.9小时和8小时及以上的人们的比例在不同年龄段的人群中不存在显著差异,原因可能是年龄段的划分不够细密,应该再多划分几个年龄段。
5假设X1,…,Xn和Y1,…,Ym分别是抽自正态总体N(a,σ2)和N(b,kσ2)的两组独立的简单样本,其中k为一已知的正数,a,b和σ2均为未知的参数。
试
(1)(10分)求出a,b和σ2的极大似然估计;
(2)(10分)根据(1)构造假设a-b的一个置信水平为1-α(0<α<1)的置信区间。
附:可能用到的上分位数
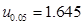 ,
,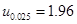 ,
,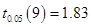 ,
,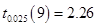 ,
,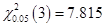 ,
,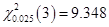
解:(1)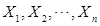 是抽自正态总体N(a,σ2)的简单样本,则
是抽自正态总体N(a,σ2)的简单样本,则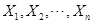 独立同分布。
独立同分布。
似然函数:
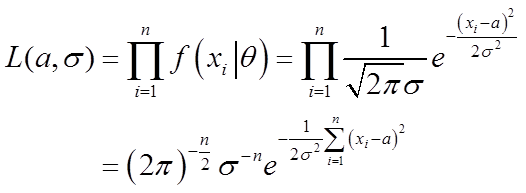
对数似然函数:
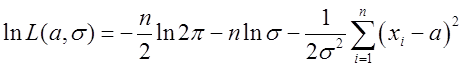
令
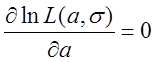
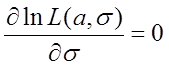
则
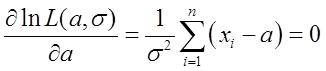
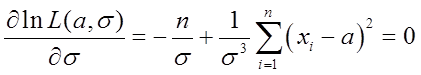
得到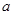 及
及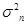 的极大似然估计分别为:
的极大似然估计分别为:
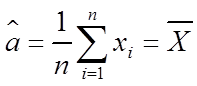
根据极大似然估计的不变性可得
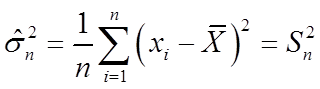
同理可求得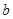 及
及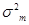 的极大似然估计为
的极大似然估计为
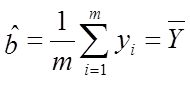
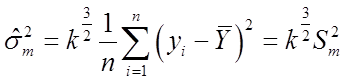
(2)①由于总体方差未知,当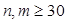 时为大样本情况,此时可用样本方差来代替总体方差。采用
时为大样本情况,此时可用样本方差来代替总体方差。采用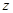 统计量。
统计量。
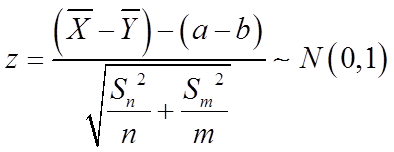
可得a-b的一个置信水平为1-α(0<α<1)的置信区间为:
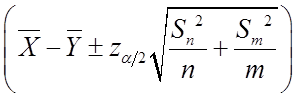
②当 时,
时,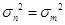 ,
,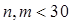 ,此时采用
,此时采用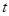 统计量。
统计量。
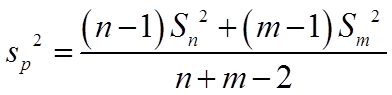
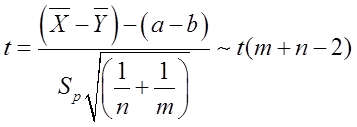
可得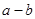 的一个置信水平为
的一个置信水平为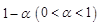 的置信区间为:
的置信区间为:
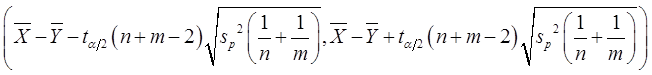
③当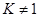 时,此时
时,此时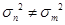 ,
,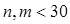 ,且
,且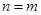 ,此时采用
,此时采用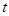 统计量。
统计量。
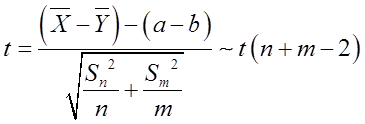
可得a-b的一个置信水平为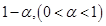 的置信区间为:
的置信区间为:
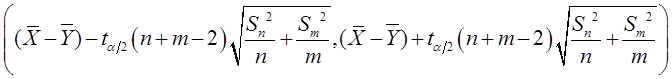
④当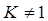 时,此时
时,此时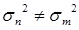 ,
,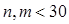 ,且
,且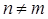 ,此时采用
,此时采用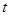 统计量。
统计量。
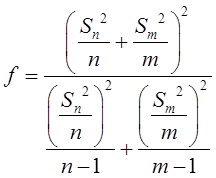
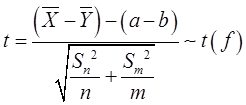
可得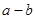 的一个置信水平为1-α(0<α<1)的置信区间为:
的一个置信水平为1-α(0<α<1)的置信区间为:
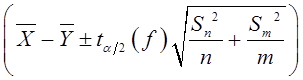
获取方式:扫码关注下面公众号,关注后

回复关键词【中国科学技术大学432】或【中国科学技术大学统计学】